Files and versioning#
Unless you’re a string theorist, at some point you’re probably going to want to save and load some data. This tutorial covers some of Sciris’ tools for doing that more easily.
Warning! The tools here are powerful, which also makes them dangerous. Unless it’s in a simple text format like JSON or CSV, loading a data file can run arbitrary code on your computer, just like running a Python script can. If you wouldn’t run a Python file from a particular source, don’t open a data file from that source either.
Click here to open an interactive version of this notebook.
Files#
Saving and loading literally anything#
Let’s assume you’re mostly just saving and loading files you’ve created yourself or from trusted colleagues, not opening email attachments from the branch of the local mafia. Then everything here is absolutely fine.
Let’s revisit our sim from the first tutorial:
[1]:
import sciris as sc
import numpy as np
import pylab as pl
sc.options(jupyter=True) # To make plots nicer
class Sim:
def __init__(self, days, trials):
self.days = days
self.trials = trials
def run(self):
self.x = np.arange(self.days)
self.y = np.cumsum(np.random.randn(self.days, self.trials)**3, axis=0)
def plot(self):
with pl.style.context('sciris.fancy'):
pl.plot(self.x, self.y, alpha=0.6)
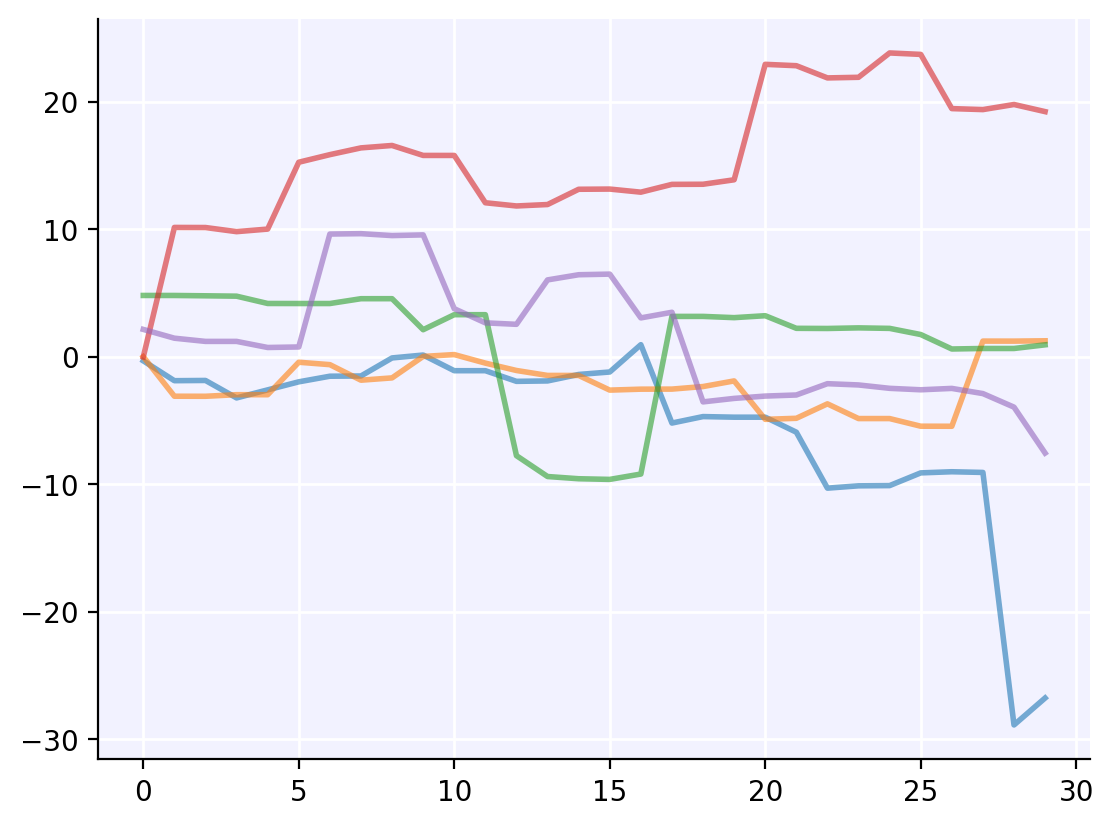
Now let’s run it, save it, reload it, and keep working with the reloaded version:
[2]:
# Run and save
sim = Sim(days=30, trials=5)
sim.run()
sc.save('my-sim.obj', sim) # Save any Python object to disk
# Load and plot
new_sim = sc.load('my-sim.obj') # Load any Python object
new_sim.plot()
We can create any object, save it, then reload it from disk and it works just like new – even calling methods works! What’s happening here? Under the hood, sc.save() saves the object as a gzipped (compressed) pickle (byte stream). Pickles are how Python sends objects internally, so can handle almost anything. (For the few corner cases that pickle can’t handle, sc.save() falls back on
dill, which really can handle everything.)
There are also other compression options than gzip (zstandard or no compression), but you probably don’t need to worry about these. (If you really care about performance, then sc.zsave(), which uses zstandard by default, is slightly faster than sc.save() – but regardless of how a file was saved you can load it with sc.load().
Saving and loading JSON#
While sc.save() and sc.load() are great for many things, they aren’t great for just sharing data. First, they’re not compatible with anything other than Sciris, so if you try to share one of those files with, say, an R user, they won’t be able to open them.
If you just have data and don’t need to save custom objects, you should save just the data. If you want to save to CSV or Excel (i.e., data that looks like a spreadsheet), you should convert it to a dataframe (df = sc.dataframe(data)), then save it from there (df.to_excel() and df.to_csv(), respectively).
But if you want to save data that’s a little more complex, you should consider JSON: it’s fast, it’s easy for humans to read, and absolutely everything loads it. While typically a JSON maps onto a Python dict, Sciris will take pretty much any object and save out the JSONifiable parts of it:
[3]:
# Try saving our sim as a JSON
sc.savejson('my-sim.json', sim)
# Load it as a JSON
sim_json = sc.loadjson('my-sim.json')
print(sim_json)
{'python_class': "<class '__main__.Sim'>", 'days': 30, 'trials': 5, 'x': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29], 'y': [[-0.32647578551687045, -0.0032164088616012444, 4.799538849988664, -0.021239402538884056, 2.137119981719019], [-1.8821254132874186, -3.1006228331825127, 4.7987477900437225, 10.132595660152653, 1.4490341434545275], [-1.864078669299369, -3.1046305247845956, 4.7729244331059935, 10.125820270458568, 1.197912359731952], [-3.233313067539922, -2.9798030003037685, 4.743844613700675, 9.801883733769131, 1.1979123774114575], [-2.6016430973261295, -2.9821280428324575, 4.170424549542263, 10.003413453052955, 0.720207363275023], [-1.9721575930241362, -0.43574700761396645, 4.167271399541883, 15.244388932817017, 0.7620434823225608], [-1.532148006063668, -0.6248848742642583, 4.167221373240443, 15.83987317452003, 9.614157920706425], [-1.512925319023791, -1.8434925174928063, 4.54520441191526, 16.369477710537666, 9.644375184271912], [-0.09826894474017522, -1.6628343675197972, 4.546301242822331, 16.558138662894144, 9.494117000911592], [0.12917792737746156, 0.020322305819717723, 2.1142794705639996, 15.777604494668935, 9.548546580597936], [-1.1000878373526712, 0.16377993088463333, 3.292039169933823, 15.776964395116378, 3.7602801545806086], [-1.0983416401199795, -0.504461136821803, 3.292103927773979, 12.067921947600441, 2.6519519488275733], [-1.934431552368316, -1.0825385592162664, -7.760017656933158, 11.815560885184702, 2.5368751609517313], [-1.9022825940943577, -1.4708261076465714, -9.395570303839298, 11.928409985720823, 6.018966725347489], [-1.3946968369537807, -1.4703597619749336, -9.569742030131827, 13.124745652840168, 6.424232224088633], [-1.2006092859461912, -2.6218210999211076, -9.62126148745036, 13.140416440711961, 6.472890554615171], [0.94044946724041, -2.5471787674173414, -9.201662187543192, 12.897450349911942, 3.0403618771770504], [-5.203818104919095, -2.541821173761128, 3.1575312611009494, 13.508994749978854, 3.4813093076498696], [-4.696294131618528, -2.341739957609263, 3.157985331255721, 13.517954834315782, -3.5439245836936175], [-4.743778469768921, -1.8997912012655764, 3.0602578319997273, 13.86836485351233, -3.2710298747337245], [-4.74344995444838, -4.91305886503669, 3.2113987907009447, 22.91930178451274, -3.088865560752716], [-5.91988781174856, -4.831229240489243, 2.2232685173147764, 22.812708284796145, -3.0039185662125285], [-10.30768186475968, -3.697817660410016, 2.2110100281521743, 21.855419965367375, -2.117539097621586], [-10.125392212875177, -4.852593769685254, 2.258726325005242, 21.903402011893583, -2.216449728870221], [-10.107807685492803, -4.852209422927621, 2.218521060148063, 23.8119228697251, -2.481521377546208], [-9.110714019546071, -5.450574807608425, 1.7365864715045418, 23.698185649261948, -2.5958289998693456], [-9.02149177947195, -5.455099509080816, 0.6023888301215023, 19.448813904821076, -2.4877652247960755], [-9.07566109374015, 1.2218821180384927, 0.6423498298648745, 19.371532721896564, -2.8936593237773343], [-28.87287987690931, 1.2191485779977616, 0.6425275941868259, 19.770656357647578, -3.956773039134549], [-26.760179273322603, 1.2455540083803944, 0.9285078809863596, 19.212432559600963, -7.557445933755042]]}
It’s not exactly beautiful, and it’s not as powerful as sc.save() (for example, sim_json.plot() doesn’t exist), but it has all the data, exactly as it was laid out in the original object:
[4]:
print(f"{sim_json['x'] = }")
print(f"{sim_json['y'][0] = }")
sim_json['x'] = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]
sim_json['y'][0] = [-0.32647578551687045, -0.0032164088616012444, 4.799538849988664, -0.021239402538884056, 2.137119981719019]
(Note that when exported to JSON and loaded back again, everything is in default Python types – so the data is now a list of lists rather than a 2D NumPy array.)
Saving and loading YAML#
If you’re not super familiar with YAML, you might think of it as that quirky format for configuration files with lots of colons and indents. It is that, but it’s also a powerful extension to JSON – every JSON file is also a valid YAML file, but the reverse is not true (i.e., JSON is a subset of YAML). Of most interest to you, dear scientist, is that you can add comments to YAML files. Consider this (relatively) common situation:
[5]:
raw_json = '''
{"variables": {
"timepoints": [0,1,2,3,4,5],
"really_important_variable": 12.566370614359172
}
}
'''
data = sc.readjson(raw_json)
print(data)
{'variables': {'timepoints': [0, 1, 2, 3, 4, 5], 'really_important_variable': 12.566370614359172}}
Now you’re tearing your hair out. Where did 12.566370614359172 come from? It looks vaguely familiar, or at least it did when you wrote it 6 months ago. But with YAML, you can have your data and comment it too:
[6]:
raw_yaml = '''
{"variables": {
"timepoints": [0,1,2,3,4,5],
"really_important_variable": 12.566370614359172 # This is just 4π lol
}
}
'''
data = sc.readyaml(raw_yaml)
print(data)
{'variables': {'timepoints': [0, 1, 2, 3, 4, 5], 'really_important_variable': 12.566370614359172}}
Mystery solved.
Other file functions#
Sciris includes a number of other file utilities. For example, to get a list of files, you can use sc.getfilelist():
[7]:
sc.getfilelist('*.ipynb')
[7]:
['tut_advanced.ipynb',
'tut_arrays.ipynb',
'tut_dates.ipynb',
'tut_dicts.ipynb',
'tut_files.ipynb',
'tut_intro.ipynb',
'tut_parallel.ipynb',
'tut_plotting.ipynb',
'tut_printing.ipynb',
'tut_utils.ipynb']
Sometimes it’s useful to get the folder for the current file, since sometimes you’re calling it from a different place, and want the relative paths to remain the same (for example, to load something from a subfolder):
[8]:
sc.thispath()
[8]:
PosixPath('/home/docs/checkouts/readthedocs.org/user_builds/sciris/checkouts/latest/docs/tutorials')
(This looks wonky here because this notebook is run on some random cloud server, but it should look more normal if you do it at home!)
Most Sciris file functions can return either strings or Paths. If you’ve never used pathlib, it’s a really powerful way of handling paths. It’s also quite intuitive. For example, to create a data subfolder that’s always relative to this notebook regardless of where it’s run from, you can do
[9]:
datafolder = sc.thispath() / 'data'
print(datafolder)
/home/docs/checkouts/readthedocs.org/user_builds/sciris/checkouts/latest/docs/tutorials/data
Sciris also makes it easy to ensure that a path exists:
[10]:
datafile = sc.makefilepath(datafolder / 'my-data.csv', makedirs=True)
print(datafile)
/home/docs/checkouts/readthedocs.org/user_builds/sciris/checkouts/latest/docs/tutorials/data/my-data.csv
Sciris usually handles all this internally, but this can be useful for using with non-Sciris functions, e.g.
[11]:
np.savetxt('data/my-data.csv', np.random.rand(2,2)) # Would give an error without sc.makefilepath() above
Lastly, you can clean up with yourself with sc.rmpath(), which will automatically figure out whether to use os.remove() (which works for files but not folders) or shutil.rmtree() (which, frustratingly, works for folders but not files):
[12]:
sc.rmpath('data/my-data.csv')
Removed "data/my-data.csv"
Versioning#
Getting version information#
You’ve probably heard people talk about reproducibility. Quite likely you yourself have talked about reproducibility. Central to computational reproducibility is knowing what version everything is. Sciris provides several tools for this. To collect all the metadata available – including the current Python environment, system version, and so on – use sc.metadata():
[13]:
md = sc.metadata(pipfreeze=False)
print(md)
#0. 'version': None
#1. 'timestamp': '2024-Apr-01 23:20:18'
#2. 'user': 'docs'
#3. 'system':
#0. 'platform': 'Linux-5.19.0-1028-aws-x86_64-with-glibc2.31'
#1. 'executable': '/home/docs/checkouts/readthedocs.org/user_builds/sciris/e
nvs/latest/bin/python'
#2. 'version': '3.11.6 (main, Feb 1 2024, 17:21:38) [GCC 9.4.0]'
#4. 'versions':
#0. 'python': '3.11.6'
#1. 'sciris': '3.1.6'
#2. 'numpy': '1.26.4'
#3. 'pandas': '2.2.1'
#4. 'matplotlib': '3.8.3'
#5. 'calling_info':
#0. 'filename': '/home/docs/checkouts/readthedocs.org/user_builds/sciris/env
s/latest/lib/python3.11/site-packages/IPython/core/interactiveshell.py'
#1. 'lineno': 3577
#6. 'git_info':
#0. 'branch': 'Branch N/A'
#1. 'hash': 'Hash N/A'
#2. 'date': 'Date N/A'
#7. 'pipfreeze': None
#8. 'require': None
#9. 'comments': None
(We turned off pipfreeze above because this stores the entire output of pip freeze, i.e. every version of every Python library installed. This is a lot to display in a notebook, but typically you’d leave it enabled.)
If you want specific versions of things, there are two functions for that: sc.compareversions(). This does explicit version checks:
[14]:
if sc.compareversions(np, '>1.0'):
print('You do not have an ancient version of NumPy')
else:
print('When you last updated NumPy, dinosaurs roamed the earth')
You do not have an ancient version of NumPy
In contrast, sc.require() will raise a warning (or exception) if the requirement isn’t met. For example:
[15]:
sc.require('numpy>99.9.9', die=False) # We don't want to die, we're in the middle of a tutorial!
/tmp/ipykernel_1428/3631962975.py:1: UserWarning:
The following requirement(s) were not met:
• numpy>99.9.9 (error: No package metadata was found for numpy>99.9.9 (available: 1.26.4))
Try "pip install numpy>99.9.9".
sc.require('numpy>99.9.9', die=False) # We don't want to die, we're in the middle of a tutorial!
[15]:
False
You can see it raises a warning (there is no NumPy v99.9.9), and attempts to give a helpful suggestion (which in this case is not very helpful).
Saving and loading version information#
Metadata-enhanced figures#
Sciris includes a copy of pl.savefig() named sc.savefig(). Aside from saving with publication-quality resolution by default, the other difference is that it automatically saves metadata along with the figure (including optional comments, if we want). For example:
[16]:
pl.pcolor(sc.smooth(np.random.rand(10,10)), cmap='turbo')
sc.savefig('my-fig.png', comments='This is a pretty plot')
[16]:
'my-fig.png'
We can load metadata from the saved file using sc.loadmetadata():
[17]:
md = sc.loadmetadata('my-fig.png')
sc.printjson(md) # Can just use print(), but sc.printjson() is prettier
{
"version": null,
"timestamp": "2024-Apr-01 23:20:18",
"user": "docs",
"system": {
"platform": "Linux-5.19.0-1028-aws-x86_64-with-glibc2.31",
"executable": "/home/docs/checkouts/readthedocs.org/user_builds/sciris/envs/latest/bin/python",
"version": "3.11.6 (main, Feb 1 2024, 17:21:38) [GCC 9.4.0]"
},
"versions": {
"python": "3.11.6",
"sciris": "3.1.6",
"numpy": "1.26.4",
"pandas": "2.2.1",
"matplotlib": "3.8.3"
},
"calling_info": {
"filename": "/home/docs/checkouts/readthedocs.org/user_builds/sciris/envs/latest/lib/python3.11/site-packages/IPython/core/interactiveshell.py",
"lineno": 3577
},
"git_info": {
"branch": "Branch N/A",
"hash": "Hash N/A",
"date": "Date N/A"
},
"pipfreeze": null,
"require": null,
"comments": "This is a pretty plot"
}
Metadata-enhanced files#
Remember sc.save() and sc.load() from the previous tutorial? The metadata-enhanced versions of these are sc.savearchive() and sc.loadarchive(). These will save an arbitrary object to a zip file, but also include a file called sciris_metadata.json along with it. You can even include other files or even whole folders in with it too – for example, if you want to save a big set of sim results and figure you might as well throw in the whole source code along with it. For example,
re-using our sim from before, let’s save it along with this notebook:
[18]:
sim_archive = sc.savearchive('my-sim.zip', sim, files='tut_files.ipynb', comments='Sim plus notebook')
Zip file saved to "/home/docs/checkouts/readthedocs.org/user_builds/sciris/checkouts/latest/docs/tutorials/my-sim.zip"
This is just an ordinary zip file, so we can open it with any application. But we can also load the metadata automatically with sc.loadmetadata():
[19]:
md = sc.loadmetadata(sim_archive)
print(md['comments'])
Sim plus notebook
And, of course, we can load the whole thing as a brand new, fully-functional object:
[20]:
sim = sc.loadarchive(sim_archive)
sim.plot()